简介
Raft是分布式一致性算法的一种。通过Leader与Follower之间的日志同步和状态机来实现分布式系统的一致性。它的作用与另外一个著名的算法Paxos类似,但是Paxos过于难以理解,导致使用Paxos的系统难以保证正确性而且出现故障时调试难度也很大。Raft算法将保证一致性的策略分为三个部分,Leader election, Log replication以及Safety,是更容易理解的一致性算法。想要学习Raft算法,这篇论文是很棒的资料 In Search of an Understandable Consensus Algorithm。本文根据这篇论文总结了一下最基本的Raft算法。
基本概念
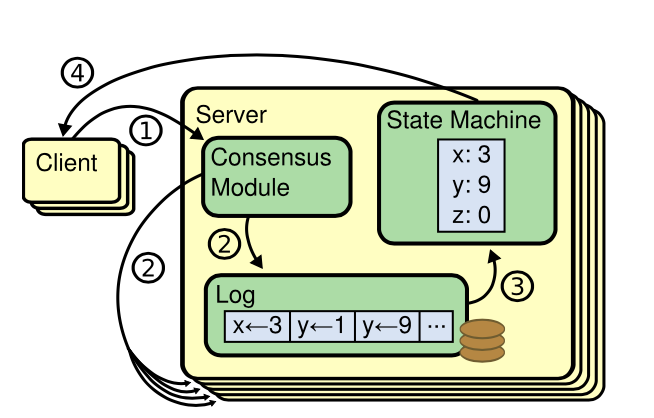
Role
Raft算法将分布式系统中的节点分为Leader,Follower和Candidate。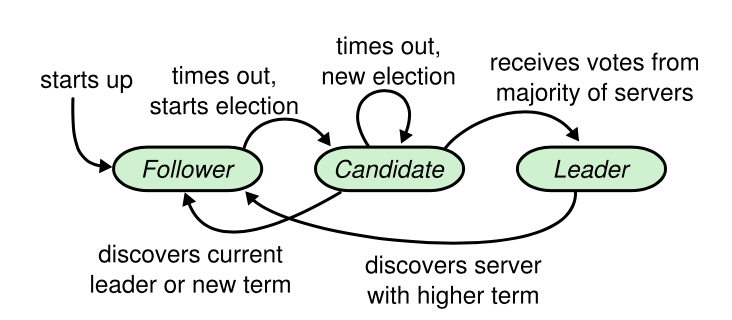
State
系统中的节点会有一些所有角色都有的状态:
currentTerm(记录当前Term)
votedFor(投票给哪个节点,默认为none)
log[](保存Log entries的队列)
以及一些部分角色有的状态:
commitIndex(该节点已commit的Log entries中最大的index)
lastApplied(该节点已被状态机执行的Log entries中最大的index)
nextIndex[](将要发送给系统中其它每个节点的Log entres的index)
matchIndex[](系统中其它每个节点已复制的Log enties的最大index)
Leader election
在每个Raft系统中会存在并且只有一个Leader,其它的节点为Follower。节点成为Leader后会给所有的Follower发送心跳包,心跳包中有可能包含待复制的Log entries也可能没有。在Follower等待时间超过超时时长后(时长一般会设置成随机的150ms-300ms防止Split votes)会将自己的角色改为Candidate并向其它节点发送RequestVote RPC请求投票,在收到超过半数节点的投票后成为Leader,并将currentTerm加1。其它节点在接收到新Leader的心跳后变为Follower。前面提到的Split votes是指有多个Follower同时成为Candidate请求投票,每个Candidate的票数相同,那么这次的选举结束,currentTerm也会加1,然后开始新一次选举。
Term
每个Leader在位时期的一个标志,在每次进行Leader election后加1。每个Term至多存在一个Leader(Split votes的状态下无Leader)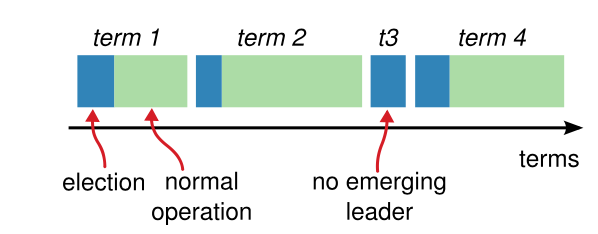
Log entry
Raft节点中用于记录客户端发来的命令的数据结构,Log entry结构包含Index,Command,Term三个属性。Index用来标记这条Log entry在队列中的位置,Command保存了客户端命令的内容,Term记录了当前Leader election的结果(每次Leader election结束后整个系统的currentTerm会加1)
Log replication
Raft节点的操作是状态机通过读取log[]队列中的内容依次执行的完成的。要达到一致性,必须保证每个节点log[]队列中的内容一致。Leader通过心跳发送AppendEntries RPC将最近到来的Log entries发送个Followers,然后Followers将收到的Log entries加入自己的log[]队列中的操作。
Log compaction
随着系统运行时间变长,Raft节点中的log[]队列的长度会不断增长。在超过一定的大小时,节点会进行Snapshot操作,将当前的状态持久化并清空log[]。Last included index和last included term记录了Snapshot前最新的Log entry的index和term。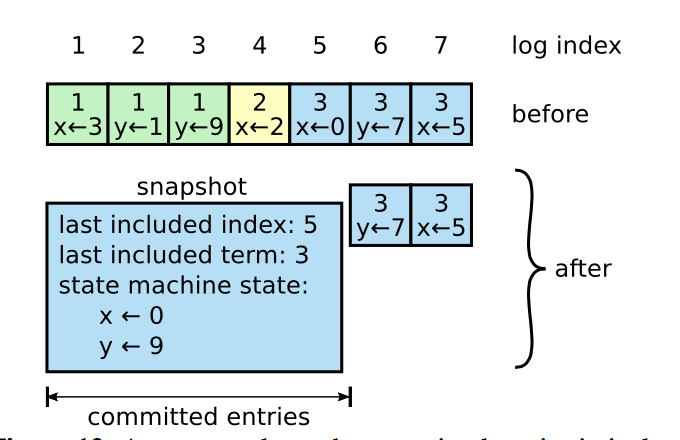
Safety
为了保证Raft算法的正确性,有以下几个Safety property。
- Election Safety:在一个Term中最多选举出一个Leader。
- Leader Append-Only:Leader不会重写或删除Log entries,只会追加Log 。entries(Election restriction:保证每次选举出来的Leader保存了所有已commit的Log entries)
- Log Matching:如果两个节点上的某个Log entry的Index和Term一致,Index在该Log entry之前的Log entries完全一致。(Committing entries from previous terms)
- Leader Completeness:如果某个Log entry在某个Term被commit,那么之后的Term的Leader都会含有这个Log entry。
- State Machine Safety:如果一个节点将某个Log entry应用到状态机中,其它节点中应用相同Index到状态机的Log entry相同。
算法描述
- 在一个Raft Group中,初始的状态是所有节点都是Follower。
- 在经过随机的超时时长后某一个Follower开始Leader election并成为Leader。并向其它Follower发送心跳。
- 客户端在请求Raft Group时只会将命令发送给Leader,Leader通过Log replication将Log entries复制到其他Follower。在收到超过半数的Follower复制成功的消息后commit该条Log entry并放到应用到状态机中。
- 状态机执行命令成功后将结果返回客户端。
- 任何节点在log[]队列增长到一定长度后将执行Snapshot操作。
- 若Leader故障,最先超时的Follower变为Candidate发起Leader election。
- 若Candidate成功成为Leader,执行2-4。若Split votes,重新开始Leader election。无论如何currentTerm加1。
- 若超过半数节点故障,整个Raft Group将故障。(没有节点能成为Leader)
- 节点故障后恢复,将接收当前Leader的心跳,发现currentTerm小于新Leader的currentTerm,自己变为Follower。
- 网络分区故障后恢复,所有Follower都会回滚未commit的Log entries并从当前Leader处复制。
最后
更多Raft算法的学习资料可以在这里找到。包括一个可视化的Raft算法执行过程以及视频讲解,还有各种语言的Raft实现。
附上我在MIT 6.824课程中的Raft实现:
https://github.com/ts25504/mit-courses/tree/master/6.824-2016/src/raft