学习MapReduce最好的资料莫过于Jeffrey Dean和Sanjay Ghemawat的论文MapReduce: Simplified Data Processing on Large Clusters。里面详细地讲述了MapReduce的来龙去脉,实现,执行过程以及在实际中的运用等等。
MapReduce是一种运行于分布式系统上的计算模型,它的思想跟分治的思想很类似,将一个大的问题划分成若干小问题,再将那些小问题并行处理最后将结果汇总得到最终的结果。MapReduce顾名思义由Map和Reduce组成,Map操作将一个大的问题划分成若干份,并以键值对的形式存储,Reduce操作以之前的键通过Hash等手段分配到若干个Reduce worker上进行计算,最终汇总得到结果。
MapReduce的算法逻辑论文中的一张图十分清晰地表现了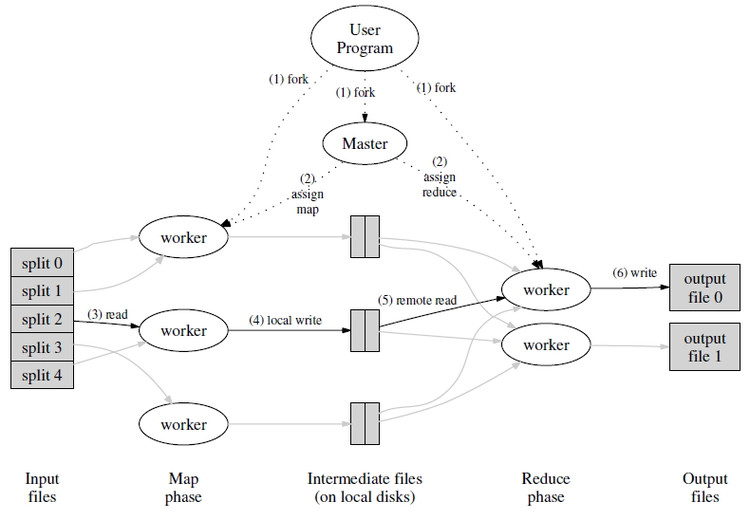
有几点需要注意的事所有Map节点和Reduce节点都是普通的Worker节点,而需要分配多少Woker节点,每个Worker是执行Map操作还是Reduce操作都是由一个单独的Master节点决定的。在执行完Map或Reduce后,执行的结果都会存储到本地磁盘进行持久化,这也是为了容灾处理,可以在节点失效后正确地恢复。
这里的讨论可以帮助我们更好地理解MapReduce的细节。